

Guardrails AI: The Safety Layer Your LLM Applications Cannot Afford to Skip
As enterprises move large language models from experimental prototypes into mission-critical production systems, a single question dominates engineering and compliance meetings alike: how do you prevent the model from doing something dangerous, leaking sensitive data, or simply producing nonsense? In 2026, with the EU AI Act's high-risk system obligations taking effect in August and enforcement penalties reaching up to seven percent of global annual turnover, the answer is no longer optional. It is guardrails — and specifically, the open-source Python framework known as Guardrails AI.
According to research compiled by Introl, 87 percent of enterprises still lack comprehensive AI security frameworks, and 97 percent of AI-related breaches in 2025 occurred in environments without proper access controls. Organizations that implemented AI-specific safety controls reduced breach costs by an average of $2.1 million. The message is unambiguous: runtime safety infrastructure pays for itself.
This article explains what Guardrails AI is, how it works, why it matters for production AI deployments, and how its layered defense philosophy aligns with established security frameworks and regulatory expectations. Whether you are building a customer-facing chatbot, an internal knowledge assistant, or an autonomous AI agent, understanding guardrails is foundational to responsible deployment.
What Exactly Is Guardrails AI?
Guardrails AI is an open-source Python framework designed to make AI applications reliable by performing two core functions. First, it runs Input and Output Guards that detect, quantify, and mitigate specific types of risks in real time — before unsafe content reaches end users. Second, it helps developers generate structured, validated data from LLMs, enforcing schema compliance so that outputs conform to expected formats.
The framework is model-agnostic. It works with OpenAI, Anthropic, open-source models, and any LLM accessible via API. At its heart is a composable validation pipeline: developers install individual risk-detection modules called validators, combine them into Guards, and wrap their LLM calls with those Guards. If a validation fails, the framework can reject the output, request a correction from the model, or apply a custom remediation action.
Guardrails vs. Model Alignment: Model alignment trains the AI itself to follow safety guidelines. Guardrails operate as an external safety layer that filters inputs and outputs independently of the model's internal training. Both are necessary — alignment shapes core behavior, guardrails catch what alignment misses.
Think of it this way: model alignment is the driver's training, and guardrails are the crash barriers on the highway. You want both, because even well-trained drivers encounter unexpected conditions.
The Guardrails Hub: A Marketplace for Safety Validators
The practical power of Guardrails AI comes from the Guardrails Hub — a community-driven collection of pre-built validators that each address a specific risk category. Rather than building detection logic from scratch, developers install purpose-built validators and compose them into comprehensive safety pipelines.
PII Detection — Validators like DetectPII use Microsoft Presidio under the hood to identify and flag personally identifiable information such as names, email addresses, phone numbers, and government IDs in both inputs and outputs. For organizations subject to GDPR or similar privacy regulations, this is a critical compliance control.
Toxic Language Detection — The ToxicLanguage validator scans text for hate speech, profanity, harassment, and other harmful language patterns. Configurable thresholds allow teams to set sensitivity levels appropriate to their use case — a children's education platform will have very different tolerance levels than an internal developer tool.
Competitor Mention Filtering — The CompetitorCheck validator prevents the model from mentioning specific competitor names in its responses. For customer-facing marketing or sales assistants, accidentally promoting a rival product is a real business risk that this validator directly addresses.
Hallucination and Factuality — Validators that compare generated text against source documents detect when the model fabricates information. For RAG-based applications where accuracy is paramount, these validators serve as a factual safety net.
Jailbreak Detection — Input validators that analyze prompts for manipulation patterns, unusual structures, or known attack signatures help prevent adversarial users from bypassing the model's intended behavior constraints.
The Hub also includes validators for SQL injection prevention, JSON and code syntax validation, language detection, gibberish detection, and many more. Developers can create custom validators and contribute them back to the Hub, making the ecosystem continuously stronger.
How Guardrails AI Works in Practice
Integration follows a straightforward pattern that adds minimal complexity to existing LLM application code.
1. Install Validators — Using the Guardrails CLI, developers install the specific validators they need from the Hub. Each validator has a unique Hub URI, making installation declarative and reproducible across environments.
2. Compose Guards — Validators are combined into a Guard object. Multiple validators can run within a single Guard, creating layered detection. For example, a single Guard might check for PII, toxic language, and competitor mentions simultaneously.
3. Wrap LLM Calls — The Guard wraps the model call. Inputs pass through input validation before reaching the model, and outputs pass through output validation before reaching the user. If any validator triggers a failure, the configured action executes — raise an exception, filter the content, or ask the model to retry.
4. Monitor and Iterate — Validation results produce structured metadata that feeds into logging, monitoring, and continuous improvement workflows. Teams can measure false positive rates, identify new risk patterns, and refine their validator configurations over time.
Pro Tip: Start with the validators that match your highest-priority risks. A financial services application might prioritize PII detection and hallucination checks, while a public-facing chatbot might prioritize toxic language and jailbreak detection. Build coverage incrementally rather than trying to implement every validator at once.
Guardrails AI in the Broader Safety Ecosystem
Guardrails AI is not the only player in the runtime safety space. Understanding where it fits helps teams make informed architectural decisions.
NVIDIA NeMo Guardrails focuses on orchestrating safety controls for agentic AI applications, with deep integration into NVIDIA's inference infrastructure and support for topic control, RAG grounding, and multi-agent deployments. It is particularly strong in GPU-accelerated, low-latency environments.
Microsoft Azure AI Content Safety provides cloud-native guardrails through the Microsoft Foundry platform, offering built-in content moderation, prompt injection defense, and agent-level safety controls. Its strength lies in tight integration with the Azure ecosystem.
OpenAI Guardrails provides a drop-in safety wrapper for OpenAI API calls, validating inputs and outputs using configurable checks. It is tightly coupled to the OpenAI ecosystem and optimized for applications built on GPT models.
What distinguishes Guardrails AI from these alternatives is its model-agnostic, open-source nature. It does not lock teams into a specific cloud provider or model vendor. Organizations running hybrid architectures — perhaps Claude for analysis, an open-source model for internal tasks, and GPT for customer-facing features — can apply consistent safety policies across all of them through a single framework.
Defense in Depth: Why Single-Layer Protection Always Fails
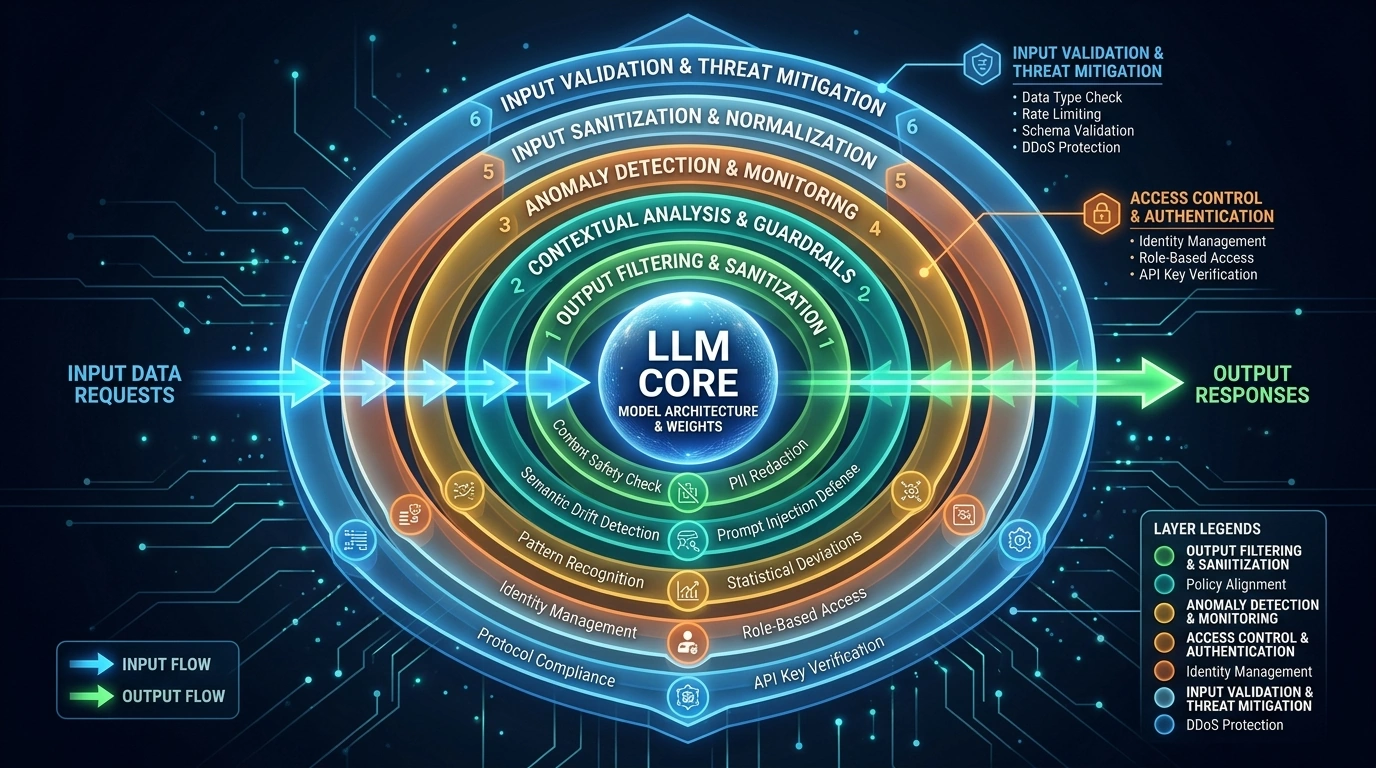
The concept behind Guardrails AI aligns with a fundamental principle in security engineering: defense in depth. No single safety mechanism can address the full spectrum of LLM risks. Prompt injection, persona swapping, indirect injection through third-party data, output manipulation, data exfiltration — each attack vector requires its own countermeasure.
Modern LLM security research identifies at least 22 distinct defense layers needed for comprehensive protection, spanning from input validation and prompt design through anomaly detection, adversarial training, session isolation, output endpoint protection, and audit logging. Guardrails AI primarily addresses the input validation, output monitoring, and structured output enforcement layers — but it integrates naturally with other layers in a complete defense architecture.
Important: Guardrails AI is a powerful runtime safety layer, but it is not a complete security solution by itself. Effective LLM security requires guardrails combined with robust prompt design, anomaly detection, rate limiting, session isolation, red teaming, and comprehensive audit logging.
The key insight is that guardrails serve as the last line of defense before unsafe content reaches users — and the first line of defense before unsafe input reaches the model. By catching what other layers miss, runtime guardrails dramatically reduce the blast radius of any single defense failure.
Regulatory Pressure Makes Guardrails Non-Negotiable
Two regulatory frameworks are driving guardrails adoption from a compliance perspective in 2026.
The EU AI Act classifies AI systems by risk level and imposes binding obligations on high-risk systems. Transparency requirements take effect in August 2026, with penalties for non-compliance reaching up to €35 million or 7 percent of worldwide turnover. For organizations deploying AI in credit scoring, recruitment, healthcare, or critical infrastructure, runtime safety guardrails are not best practice — they are a regulatory requirement.
The NIST AI Risk Management Framework provides a voluntary but increasingly referenced structure for AI governance in the United States. Its four core functions — Govern, Map, Measure, and Manage — map directly to the guardrails paradigm. Input/output validation satisfies elements of the Measure and Manage functions, while the audit trails generated by guardrails support the Govern function's accountability requirements.
For organizations operating across both markets, implementing a guardrails framework like Guardrails AI provides a practical foundation for demonstrating compliance with both regulatory regimes simultaneously.

Guardrails in SEO and Content Intelligence Platforms
The guardrails paradigm extends beyond chatbots and general-purpose assistants. Any platform that integrates LLM capabilities into its workflow benefits from runtime safety controls.
At OnPagePilot, AI-powered features operate across indexing, content analysis, and natural language processing pipelines — all built on a .NET 10 backend architecture with multiple database shards and distributed background services. When AI generates content suggestions, keyword analyses, or structural recommendations, those outputs must be accurate, free from hallucination, and appropriately scoped to the user's domain. Runtime validation ensures that AI-generated insights meet quality thresholds before they influence a customer's SEO strategy. The same defense-in-depth philosophy that Guardrails AI implements at the framework level — input filtering, output validation, structured enforcement — applies at the architectural level in any platform where AI touches business-critical decisions.
Getting Started with Guardrails AI
Adoption is straightforward for teams already building Python-based LLM applications. Install the framework via pip, configure the Hub CLI with a free API key, install validators from the Hub, and wrap your existing LLM calls with Guard objects. The framework supports both synchronous and asynchronous execution, server deployment for centralized governance, and integration with orchestration frameworks like LangChain and LlamaIndex.
For teams using other languages, Guardrails AI provides a JavaScript bridge that runs the underlying Python library via an I/O interface, enabling cross-language integration. The open-source repository on GitHub contains comprehensive documentation, quickstart guides, and example patterns for common use cases.
The most important step is not choosing the perfect set of validators — it is deploying any guardrail at all. Organizations with even basic runtime safety controls consistently outperform those with none, both in incident prevention and regulatory readiness. Start with your highest-risk surface area and expand coverage as your team gains operational experience.
Conclusion
Guardrails AI is an open-source Python framework that adds runtime safety to LLM applications through composable input and output validation. Its Hub-based validator ecosystem makes it practical to address specific risks — PII leakage, toxic language, hallucination, jailbreak attempts, and structural violations — without building detection logic from scratch. Its model-agnostic design means a single safety policy can protect applications regardless of which LLM provider powers them.
In a regulatory environment where the EU AI Act mandates documented safety controls for high-risk AI systems and the NIST AI RMF provides a widely adopted governance blueprint, runtime guardrails have moved from nice-to-have to necessity. The AI content moderation market is projected to grow from approximately $1 billion in 2024 to $2.6 billion by 2029, reflecting the scale of investment flowing into exactly this problem space.
The organizations that thrive in this landscape will not be those with the most powerful models. They will be those with the most reliable safety infrastructure around their models. Guardrails AI provides a practical, extensible foundation for building that infrastructure today.
Further Reading
- Guardrails AI Official Documentation — Complete framework documentation, quickstart guides, and API reference for building Guards and using validators
- Guardrails AI GitHub Repository — Source code, installation instructions, and community contributions for the open-source framework
- NIST AI Risk Management Framework — The foundational US governance framework for AI risk management with Govern, Map, Measure, and Manage functions
- EU AI Act — European Commission — The first comprehensive AI regulatory framework with risk-based classification and binding compliance obligations
- Palo Alto Networks Unit 42 — Comparing LLM Guardrails — Comparative research study evaluating guardrail effectiveness across major GenAI platforms