The Guardrail Pipeline
Enterprise-Grade AI Safety with 22 Layers of Defense
Executive Summary: Beyond the "Single Filter" Myth
In an era of evolving LLM threats, a single safety filter is no longer sufficient. This whitepaper introduces the Guardrail Pipeline, a defense-in-depth architecture consisting of 22 distinct layers of security. By segmenting defense into four critical stages—Input, Logic, Inference, and Output—organizations can maintain operational reliability while neutralizing complex jailbreaking attempts.The Guardrail Pipeline: Data-Flow Visualisation
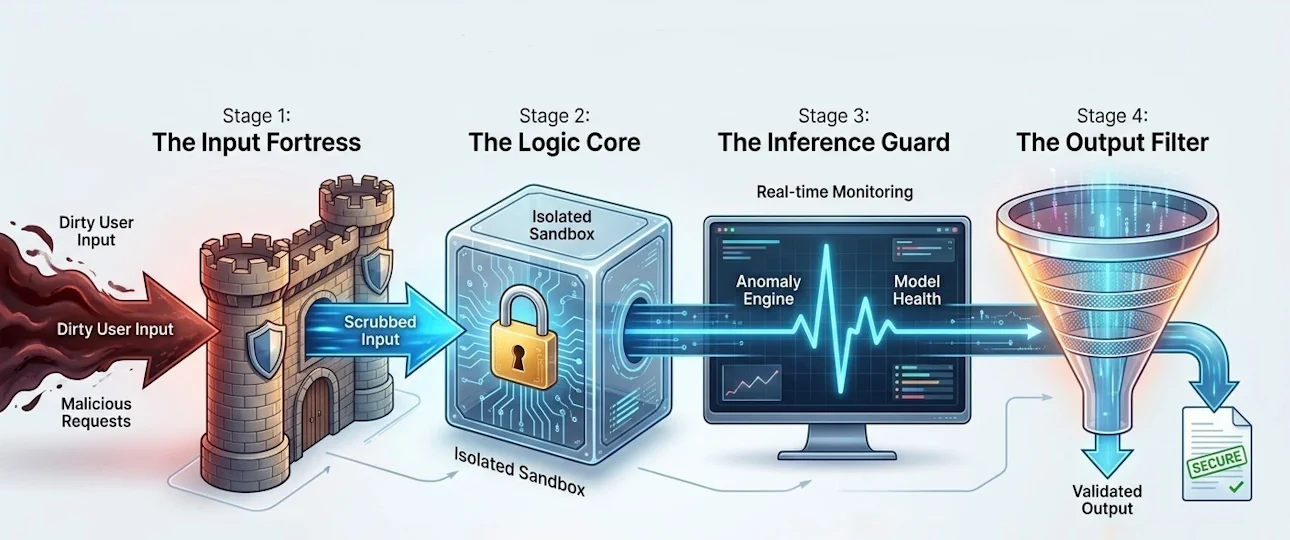
The Input Fortress
Incoming requests are instantly scrubbed for injections, hidden laundering, and rate-limit anomalies.
The Logic Core
The request is framed within a robust, isolated sandbox. Persona validation ensures the AI never deviates from its expert role.
The Inference Guard
During processing, our anomaly engine monitors computational health and behavioral drift in real-time.
The Output Filter
Final verification. Output is checked against your business contracts, PII-leaks are blocked, and traceability is embedded.
-
Sanitization & Validation: Aggressive filtering of user prompts to remove known injection strings and normalize character encoding.
-
Invisible Threat Detection: Identifying "prompt laundering" and hidden text—such as white-on-white or zero-width characters—embedded in documents or third-party data.
-
Traffic Governance: Utilizing API rate limiting and quota controls to stop automated brute-force jailbreak attempts
-
Contextual Adaptivity: Data Integrity: Securing the foundation by scanning pre-training corpora for "data poisoning" or embedded backdoors.
-
Architecture Hardening: Implementing robust prompt design with clear role descriptions and meta-instructions to ignore bypass attempts
-
Persona Integrity: Automated detection of role-play attempts, preventing the model from adopting unauthorized personas designed to bypass safety.
-
Execution Isolation: Running interactions within isolated sandboxes to prevent privilege escalation or data leaks between sessions.
-
Contextual Intelligence: Adjusting filtering strength based on user roles and the sensitivity of the data being accessed.
-
Behavioral Monitoring: Statistical baselining to flag unusual token composition or shifts in model behavior that suggest a successful jailbreak.
-
Resource Protection: Real-time monitoring of GPU time and VRAM to prevent "Denial-of-Wallet" attacks caused by recursive or overly complex prompts.
-
Adversarial Resilience: Leveraging models that have undergone adversarial training to recognize and reject novel attack patterns during inference.
-
Alignment Feedback: Utilizing RLHF (Reinforcement Learning from Human Feedback) to continuously improve the model's "refusal skills"
-
Policy Enforcement: Automatic scanning of outputs for toxicity, PII leaks, or code that violates corporate security policies.
-
Contractual Compliance: Enforcing fixed schemas (JSON/XML) to ensure the model cannot smuggle sneaky instructions or unstructured data.
-
Traceability & Attribution: Embedding nearly invisible watermarks in text to track model-generated output and document misuse.
-
The Emergency Brake: Utilizing "Model Unlearning" to surgically edit vulnerabilities out of the model weights in minutes when new zero-day jailbreaks are discovered.
AI Security & Enterprise Compliance
Frequently Asked Questions
Built on over 35 years of technical expertise and tactical precision, OnPagePilot offers an enterprise-ready infrastructure with full EU AI Act compliance, a strict policy on user data and real-time output verification — we ensure your content not only ranks but meets the highest professional standards for authority and trust.
Experience the future of secure AI workflows — engineered for those who require absolute control and uncompromising performance.
We employ a multi-layered defense-in-depth architecture consisting of 22 independent security layers. This includes real-time input sanitization (Layers 1-6), randomized delimiters (Layers 7-10) to prevent instruction overrides, and behavioral anomaly detection (Layers 21-22). Our "Security Engine" scans every interaction in real-time to identify and neutralize adversarial patterns before they reach the model.
No. We have a strict "No-Training" policy. Any data processed through OnPagePilot, including your prompts, proprietary business intelligence, and generated content, is never used for training OpenAI's GPT models or any other third-party LLMs. Your intellectual property remains yours and yours alone.
OnPagePilot is built with "Compliance-by-Design." We address the core requirements of the EU AI Act by providing full traceability (Layer 19), automated risk mitigation protocols (Article 9), and advanced tools for human oversight (Article 14). Our 22-layer framework ensures that we meet the transparency and robustness standards required for professional AI applications.
All data is encrypted in transit using industry-standard TLS (Transport Layer Security) and at rest using AES-256 encryption. Our infrastructure is hosted on secure, enterprise-grade Windows Server environments with dedicated SQL Audit Trails (Layer 19), ensuring that every data movement is logged and traceable for internal audits.
Yes. We support enterprise transparency. You can download our technical "AI Security & Jailbreak Defense" whitepaper directly from this page. For deeper security assessments or specific compliance questionnaires, our Data Protection Officer (DPO) is available to assist your IT-security team.
Our security pipeline is engineered for high-performance throughput, processing over 1.3 million log lines per second with parallelized validation layers. The "Security Engine" adds negligible latency (typically <15ms) to the inference process, ensuring that absolute security does not compromise user productivity.